
FONÉTICA
La fonética es la disciplina que se ocupa de estudiar los aspectos fónicos de la lengua, es decir, todos los aspectos relacionados con los sonidos lingüísticos: su producción, su percepción, sus posibilidades de combinación, etc.
La fonética es la disciplina lingüística que estudia los sonidos de las lenguas humanas.
En la ciencia es habitual dividirse el trabajo y que cada subdisciplina realice un análisis diferente sobre un objeto parcialmente compartido. Así, las subdisciplinas de la fonética estudian distintos aspectos relacionados con los sonidos lingüísticos:
- la fonética acústica se ocupa de estudiar las características físicas de las ondas sonoras del habla
- la fonética articulatoria se ocupa de estudiar cómo se articulan los sonidos del habla, es decir, se ocupa de las propiedades que dependen de cómo se mueven los órganos articuladores
- la fonética perceptual (o auditiva) se ocupa de estudiar cómo se percibe el habla, es decir, de las propiedades que dependen de nuestros órganos auditivos
Por lo tanto, si analizamos cualquier sonido lingüístico podremos decir algo sobre sus propiedades físicas (fonética acústica), sobre cómo los producimos (fonética articulatoria) y sobre cómo se perciben. Pero, ¿qué es el sonido, y en particular, qué es un sonido lingüístico? ¿Qué hace que un sonido sea lingüístico o no?
Fonética acústica
Caracterización física del sonido
El sonido es una sensación que percibimos los seres humanos y algunos animales a través de nuestros oídos. Esa sensación es el resultado de las vibraciones de uno o varios cuerpos. Al vibrar un cuerpo, por la razón que sea, produce un cambio de presión en el aire que lo rodea. Una perturbación en el aire. El aire, perturbado, cambia de forma, porque es elástico. Y como es elástico, también vuelve a su forma anterior.
El aire perturbado por la vibración de un cuerpo funciona igual que una masa de agua. Si algo se mueve, el material elástico que lo rodea (agua o aire) se perturba y las partículas que lo forman se mueven en forma de onda. Una única vibración, como una única gota en un lago plácido, produce una única serie de ondas. Múltiples vibraciones producen múltiples ondas.

Una onda es una perturbación que se propaga desde el punto en que se produjo hacia todo lo que está alrededor de ese punto. Si lo que está alrededor de ese punto es un medio elástico como el aire o el agua, ese medio se deforma y se recupera vibrando al paso de la onda. La onda se repite: es una onda periódica.
Las ondas sonoras transportan energía y cantidad de movimiento pero no transportan materia: las partículas vibran alrededor de la posición de equilibrio y se mueven un poco, pero no viajan con la perturbación: se alejan un poco y vuelven al mismo punto, varias veces, hasta que termina. Es decir, el sonido no es una partícula que golpea nuestros oídos, sino un cambio de la energía en el aire que nos rodea. Ese cambio de presión en el aire produce un vaivén de partículas cuyo movimiento puede describirse matemáticamente como un movimiento ondulatorio.

La física es la disciplina que estudia el comportamiento de las partículas del mundo físico. Gracias a la física, y en particular a la acústica, podemos calcular las propiedades de las distintas ondas y medir las propiedades físicas de los sonidos.
Para producir ondas sonoras simples puras se utiliza un diapasón. Los oscilogramas (i.e. los gráficos que describen las ondas sonoras) de la onda producida por un diapasón y de las ondas producidas por la voz humana son muy diferentes. Las vibraciones del diapasón trazan lo que los matemáticos denominan una onda sinusoidal, una curva ondulada que, en teoría, podría repetirse para siempre, una onda periódica. En contraste, los gráficos del habla muestran una serie de picos agudos, sin oscilaciones.

Los sonidos lingüísticos
Los sonidos del habla, llamados técnicamente alófonos o, directamente, fonos) son el resultado de la combinación de ondas simples producidas por la interacción de la presión del aire en la cavidad bucal y la posición y el movimiento de los órganos fonadores. Dado que la acústica es la disciplina de la física que estudia las propiedades físicas del sonido, la fonética acústica recurre para el análisis de los sonidos lingúísticos a los métodos habituales de representación y análisis de la física.
Desde el punto de vista acústico, toda onda sonora se caracteriza por medio de la duración, que se mide en milisegundos (ms), de la frecuencia, que se mide en hercios o hertz (Hz) y de la amplitud, que se mide en decibeles (db) y se relaciona con la intensidad.

La duración es el tiempo durante el cual se mantiene un sonido; físicamente está determinada por la longitud de onda, es decir la distancia entre el principio y el final de una onda completa (ciclo); según esto podemos decir que por duración los sonidos pueden ser largos o breves. Intenten producir un sonido vocálico largo y compárenlo con uno breve. Fácil. Fáacil.
La frecuencia representa cuántos ciclos (cuántas ondas completas) se producen por unidad de tiempo, y se vincula con el tono: a mayor frecuencia, es decir, a más cantidad de ondas en una unidad de tiempo, el sonido es más agudo, y a menor frecuencia -menos cantidad de ciclos por unidad de tiempo- el sonido es más grave. Intenten producir un sonido vocálico grave y otro agudo sin cantar. En español, las diferencias de frecuencia se manifiestan en la entonación. Diferentes tonos pueden tener diferentes significados. No. ¿No?

Una frecuencia de 440hz es habitualmente considerada la frecuencia de la nota pura LA. Como la escala de tonos va de más graves a más agudos (do-re-mi-fa-sol-la-si), Sol tiene menor frecuencia que La y Si tiene mayor frecuencia. La fonética auditiva nos dice que las frecuencias audibles para el ser humano se encuentran entre 20 Hz y 20000 Hz. No podemos escuchar ni los infrasonidos (frecuencias por debajo de 20hz) ni los ultrasonidos (frecuencias superiores a 20000hz). Los perros, en cambio, captan sonidos de entre 40 y 46.000 hertz y los caballos, de entre 31 y 40.000; aparentemente los elefantes y las vacas advierten incluso los infrasonidos.
La a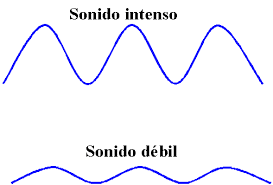 mplitud se relaciona parcialmente con la distancia que recorre la partícula perturbada antes de volver a su posición inicial. A mayor amplitud, mayor intensidad. La intensidad se mide en decibeles y se representa en el eje vertical del oscilograma. Los sonidos audibles oscilan entre el umbral auditivo de 0 dB en el que no se escucha y el umbral de dolor de 140 dB en el que se produce lesión auditiva. Intenten producir dos sonidos consecutivos con distinta intensidad: [PApa]. [paPA]. En español, las diferencias de intensidad tienen una importante carga de significado, ya que se asocian al acento: Papa. Papá.
mplitud se relaciona parcialmente con la distancia que recorre la partícula perturbada antes de volver a su posición inicial. A mayor amplitud, mayor intensidad. La intensidad se mide en decibeles y se representa en el eje vertical del oscilograma. Los sonidos audibles oscilan entre el umbral auditivo de 0 dB en el que no se escucha y el umbral de dolor de 140 dB en el que se produce lesión auditiva. Intenten producir dos sonidos consecutivos con distinta intensidad: [PApa]. [paPA]. En español, las diferencias de intensidad tienen una importante carga de significado, ya que se asocian al acento: Papa. Papá.

Los físicos han desarrollado formas de cálculo que permiten estimar con excelente precisión el comportamiento de las ondas sonoras en diferentes condiciones. En el siglo XIX, los matemáticos perfeccionaron la teoría de Jean Baptiste Joseph Fourier, un matemático francés. Fourier afirmó en 1807 que cualquier forma de onda repetitiva (es decir, una onda que se repite o períódica, como la onda sonora de un diapasón) se puede expresar como una suma infinita de ondas de diversas frecuencias que sean múltiplos de la frecuencia más grave. La onda de frecuencia más baja (la de tono más grave) se denomina frecuencia fundamental de la nota, y las de mayor frecuencia se denominan armónicos. Por ejemplo, la nota La, en un violín o una flauta, tiene una frecuencia fundamental de 440 ciclos por segundo y armónicos con frecuencias de 880, 1320 y así sucesivamente. Aunque un violín y una flauta toquen la misma nota, el sonido será distinto porque ambos instrumentos tienen diferente timbre y porque sus armónicos tienen distinta fuerza o amplitud.
Se dice, entonces, que los sonidos periódicos pueden caracterizarse por su estructura formántica: una frecuencia fundamental y una serie de frecuencias armónicas. Esta estructura de formantes puede verse en en un espectrograma.

El instrumento actualmente más utilizado para el análisis fonético del habla es un software llamado Praat (del holandés “hablar”). Es un programa gratuito diseñado y en continua actualización por Paul Boersma y David Weenink de la Universidad de Amsterdam. Aunque en este curso no tendrán que hacer cálculos ni aprender a utilizarlo, sepan que su manejo es una de las competencias necesarias para el trabajo del lingüista que se dedica al análisis fonético del habla.

Praat es capaz grabar la voz en varios tipos de archivos de audio y mostrar los espectrogramas, identificando los formantes. Además, permite el análisis de la entonación y de la intensidad.
Caracterización acústica de las vocales.
Las vocales son los sonidos que se perciben con mayor facilidad precisamente porque el sonido se compone de varias ondas armónicas que resuenan con mayor claridad y sonoridad.
Acústicamente, los sonidos vocálicos están constituidos por una onda sonora periódica compleja, cuyo perfil se repite a intervalos regulares de tiempo. Este perfil es el resultado de la vibración de las cuerdas vocales en la glotis.
La onda sonora producida experimenta el fenómeno de la resonancia cuando atraviesa las cavidades y, de este modo, se amplifican algunos de sus armónicos. La configuración de las cavidades de resonancia es distinta para cada vocal, porque la posición de la lengua varía agrandando o achicando la caja de resonancia.
Las ondas sonoras vocálicas son periódicas, es decir, se trata de ondas que se repiten durante un período de tiempo. Además, como la cavidad oral funciona como una caja de resonancia, las vocales están formadas por varias ondas diferentes armónicas. Cada onda armónica, es decir, cada formante (F), tiene su propia caracterización acústica independiente. Cada vocal (es decir, cada onda periódica) puede caracterizarse por medio de hasta 4 formantes (F0, F1, F2, y F3). F0 es la frecuencia fundamental, y F1, F2 y F3 sus armónicos.
El timbre vocálico depende de las frecuencias de los formantes: las vocales /o/ y /u/ son las más graves, porque F1 y F2 se encuentran en el rango más bajo de las frecuencias, mientras que la /e/ y la /i/ son agudas porque F1 y F2 se encuentran en la zona más alta del espectro. Una de las maneras más habituales de representar la estructura formántica de las vocales es por medio de en un gráfico llamado carta de formantes. La carta de formantes representa la relación entre los formantes F1 y F2. En el eje x se establecen los valores de F1 y en el eje Y los valores de F2. Esa relación permite ver que las vocales se distribuyen con un patrón “triangular” (aunque, en realidad, es más bien trapezoidal)


Caracterización acústica de las consonantes
En general, la mayoría de las consonantes son sonidos aperiódicos, ya que la onda no se repite. Existe, sin embargo, un grupo de consonantes sonantes, que son sonoras, e igual que las vocales, presentan una onda sonora periódica compleja. En español existen tres clases de consonantes sonantes: la lateral ([La], las nasales [ma, na, ña] y las vibrantes ([Ra, ara])
PROSODIA
La prosodia es una subdisciplina de la fonética que estudia los fenómenos acústicos que afectan a uno o varios segmentos fonéticos simultáneamente. Se dice que son factores suprasegmentales porque son resistentes a la segmentación: la prosodia no identifica sus unidades por medio del método de segmentación y sustitución, ya que los rasgos prosódicos pueden afectar a un único segmento (como el acento de intensidad) o a un grupo de segmentos (como la entonación interrogativa, por ejemplo), sin que sea posible separar claramente el fenómeno prosódico del segmento. Todos los segmentos fónicos tienen algún factor prosódico asociado, aunque nunca puedan separarse los segmentos de los “suprasegmentos” o rasgos prosódicos.
Acentuación
Los factores prosódicos nos permiten identificar distintos patrones de acentuación léxica (es decir, de acentuación de las palabras). Identificamos, entonces, que las palabras del español pueden ser átonas (sin acento léxico) o tónicas (con acento léxico).
Las palabras tónicas pueden ser graves, agudas o esdrújulas. El acento léxico en español se ubica en lo que se llama la ventana de las tres últimas sílabas. Así, técnicamente, hablamos de palabras oxítonas (agudas), paróxitonas (graves) o proparoxítonas (esdrújulas) según en qué sílaba esté el acento.
A su vez, las palabras en secuencia se agrupan alrededor de uno de los acentos léxicos acento primario, formando lo que se llama un grupo acentual:
en el coche // una pregunta // no salieron
Prosódicamente, además, los hablantes podemos destacar alguna sílaba, palabra o secuencia de palabras por medio de la entonación. Dado que la entonación lleva una parte de significado importante, lo veremos en la sección Fonología.
FONÉTICA ARTICULATORIA
La fonética articulatoria estudia cómo se articulan los sonidos lingüísticos.
¿Cómo se producen los sonidos lingüísticos?
Los sonidos lingüísticos son sonidos que se producen por el paso del aire pulmonar a través de la tráquea, la faringe y la laringe y de las cuerdas vocales hasta que sale por la boca y/o la nariz. El aparato fonador está integrado por varios órganos que sirven también para respirar y para comer: los pulmones, los bronquios, la tráquea y la laringe, las cuerdas vocales, la glotis, la cavidad bucal (oral), la cavidad nasal y la cavidad faríngea.

La respiración, la fonación y la articulación son los tres mecanismos que intervienen en la producción de los sonidos del habla. Durante la respiración (espiración e inspiración), se crea la columna de aire.
La articulación es el conjunto de movimientos que realizan los órganos para producir los sonidos del habla.
En la fonación, el aire sube por la tráquea, llega a la laringe y a las cuerdas vocales y sale después de atravesar las cavidades superiores. Las cuerdas vocales son dos pliegues que cortan la faringe transversalmente, que se abren y cierran o vibran con el paso del aire. Pueden ver en este vínculo las cuerdas vocales en funcionamiento con un estroboscopio laríngeo, o, más divertido, ver las cuerdas vocales de Steven Tyler mientras canta.
La articulación es el conjunto de movimientos que realizan los órganos para producir los sonidos del habla. En los movimientos articulatorios intervienen la lengua y los labios.
En el siguiente video, podrán ver cómo un simple ecógrafo (el mismo que se utiliza para controlar la evolución del embarazo y conocer el sexo del bebé) y una animación superpuesta al video nos permiten “ver” qué es lo que sucede dentro del aparato articulador.
Articulatoriamente, todas las lenguas del mundo se forman con sonidos que los hablantes producen con las mismas partes del cuerpo con las que respiran y comen, y todas las lenguas del mundo se forman combinando dos clases de sonidos muy diferentes: sonidos vocálicos y sonidos consonánticos.
Todas las lenguas del mundo se forman combinando dos tipos de sonidos diferentes: vocálicos y consonánticos.
¿En qué se distinguen articulatoriamente los sonidos vocálicos de los consonánticos? La principal diferencia articulatoria reside en que en los sonidos vocálicos el aire sale libremente, sin ningún tipo de obstrucción, mientras que en los sonidos consonánticos hay algún tipo de obstrucción en la salida del aire.
En el siguiente video, podrán ver imágenes tomadas con otro tipo de tecnología, la resonancia magnética en tiempo real (rtMRI) de dos cantantes, una voz femenina cantando ópera y una masculina rapeando. Verán que se puede distinguir claramente cómo la cantante de ópera aprovecha la apertura de los sonidos vocálicos para generar los efectos melódicos de la ópera, mientras que el rapero aprovecha la constricción de los sonidos consonánticos para generar los efectos rítmicos del rap.
Cuando se trabaja con la descripción de los sonidos, es importante tener cuidado con la forma de representarlos, para no confundir la escritura con el sonido. Para eso, existe un alfabeto fonético internacional (AFI) elaborado por la Asociación de Fonética Internacional. El AFI está constituido por una serie de caracteres y un conjunto de diacríticos que permiten representar todos los sonidos del habla de forma unívoca y asociados a sus características articulatorias. La primera versión del AFI se publicó en 1866. Regularmente la Asociación de Fonética Internacional revisa el AFI y lo modifica en función de las necesidades de representación lingüística y de los medios técnicos disponibles.
Existe una versión simplificada del AFI desarrollada en la Unión Europea llamada SAMPA (Speech Assessment Methods Phonetic Alphabet). Se diseñó como un alfabeto fonético legible por computadora mediante caracteres ASCII de 7 bits. En el siguiente vínculo encontrarán una tabla de correspondencia entre los caracteres AFI y los caracteres SAMPA para el español rioplatense elaborada por un equipo de investigadores argentinos (Gurlekian, Colantoni y Torres, 2001)
Los sonidos, entonces, se transcriben fonéticamente en un tipo de escritura particular, en la que un mismo sonido es representado siempre con el mismo símbolo. Los sonidos que se transcriben se representan siempre entre corchetes. Así, podemos decir, usando el AFI, que la palabra cien se pronuncia de manera diferente en Madrid y en Mar del Plata: en Madrid se pronuncia [Ɵien] y en Mar del Plata [sien]. Por eso es muy importante escribir entre corchetes las transcripciones fonéticas.
Fragmento descargado el 18/9/18 de la página https://enunciate.arts.ubc.ca/linguistics/introductory-videos/ perteneciente al proyecto “Multimodal approaches to the empowerment of pronunciation teaching and learning: Creating online interactive tutorial videos” (PI: Bryan Gick) funded by flexible learning Teaching and Learning Enhancement Fund. Universidad de British Columbia. Fragmento recortado con clipconverter.cc
Las vocales. Caracterización articulatoria.
Durante la producción de los sonidos vocálicos, el flujo de aire no encuentra ningún obstáculo en su salida y produce una vibración de las cuerdas vocales. Ustedes pueden sentir esa vibración si ponen suavemente los dedos en su cuello, a la altura de la laringe, y pronuncian algunas vocales. Se dice que un sonido es sonoro cuando se produce con vibración de las cuerdas vocales. Todas las vocales son sonoras.
Un sonido lingüístico es “sonoro” cuando se produce con vibración de las cuerdas vocales. Las vocales son siempre sonoras. Se describen por medio de la altura (height) y la posición de la lengua (backness) y del redondeamiento de los labios.
¿Cómo se producen las diferencias de sonidos vocálicos? Por las diferentes posiciones que toman los labios y el dorso de la lengua en la cavidad bucal y por el lugar por dónde sale el aire. (Recuerden el video de la diva y el rapero).
Una vocal es alta cuando el dorso de la lengua se eleva en relación a su posición de descanso y se acerca al paladar. Es baja cuando la lengua desciende y se aleja del paladar y media cuando se mantiene en un punto medio. Hagan el intento: digan [iiii] y luego digan [eeee]. Digan [uuuu] y luego [oooo]. ¿Dónde está la lengua en cada caso en relación con el paladar? ¿Cuál es alta y cuál es baja? Exacto. La [i] es alta y la [e] es baja. La [u] es alta, la [o] es más baja.
Articulatoriamente, además, las vocales se diferencian por la forma como la lengua se adelanta hacia los dientes o retrocede hacia el velo del paladar. Si la lengua se adelanta, tenemos vocales anteriores y si retrocede, vocales posteriores. Ahora pronuncien [iii] y luego [uuu]. Pronuncien [eeee] y luego [oooo]. ¿Qué pasó con la posición de la lengua en relación a los dientes? Exacto. La [i] es anterior, la [u] es posterior. La [e] es anterior, la [o] es posterior.
En el siguiente fragmento de video van a observar una serie de animaciones que representan la articulación de las vocales básicas. Si bien está elaborado para el inglés, la información y los sonidos que representan son bastante similares a las vocales equivalentes del español.
El español es una lengua con pocas vocales. Otras lenguas tienen muchas más vocales que el español, con diferentes articulaciones. Por ejemplo, si el aire también sale por la nariz, no solo por la boca, las vocales son nasales. En español la nasalidad de las vocales no es un rasgo característico, como sí lo es, por ejemplo, en francés.
Las consonantes. Caracterización articulatoria.
Articulatoriamente, en cambio, las consonantes siempre tienen algún tipo de restricción a la salida de aire. Esa restricción es muy diferente según se trate de consonantes obstruyentes o sonantes.
Las obstruyentes se caracterizan por ser sonidos oclusivos o fricativos. Es decir, sonidos en los que el aire queda atrapado en la cavidad oral o en los que el aire sale con alguna fricción.
Las consonantes sonantes, en cambio, se caracterizan por que, durante su realización, el aire sale sin fricción ni explosión, y las cavidades oro-naso-faríngeas actúan como caja de resonancia. Son más sonoras que las obstruyentes.
Desde el punto de vista articulatorio, las consonantes pueden describirse, entre otros factores, por su modo de articulación (manner of articulation), por el lugar de la articulación (place of articulation) y por la sonoridad (voicing) es decir, la presencia o ausencia de vibración de las cuerdas vocales.
Pueden seguir la lectura con el siguiente video, que les muestra las propiedades necesarias para describir las vocales del inglés. Pronto veremos específicamente las del español.
El modo de articulación distingue los sonidos consonánticos por la forma en la que se expulsa el aire. Si existe una obstrucción parcial de los órganos articulatorios y el aire sale con una fricción, el sonido es fricativo. En cambio, si la obstrucción es total y se impide por completo el paso del aire, el sonido es oclusivo. Observen la diferencia entre decir [efe] y decir [eme]. Intenten mantener el sonido [f] y el sonido [m] mientras ponen la mano frente a los labios. ¿Sienten cómo sale el aire en [f] pero no sale nada de aire en [m]? Esa es la diferencia entre un sonido fricativo (el que sale con fricción), y uno oclusivo (en el que no sale aire).
Ejemplo de articulación consonántica (sonido /p/ del inglés). En inglés, además, el sonido [p] es explosivo, el aire sale de manera más violenta que en español, donde solo es oclusiva pero no plosiva.
Por el lugar de articulación, el sonido [m] y el sonido [f] se distinguen también: para decir [m] solo juntamos los labios, mientras que para decir [f] ponemos los dientes junto a los labios. Decimos entonces que, por su lugar de articulación, [m] es un sonido bilabial y [f] labio-dental. El lugar de articulación permite caracterizar los sonidos consonánticos por el lugar de la cavidad oral donde se produce el obstáculo que impide o dificulta la salida del aire. Si la obstrucción la producen los labios, serán consonantes bilabiales. Si la produce la punta de la lengua (ápice) contra los dientes serán dentales, y alveolares si se apoya contra los alvéolos. Si la obstrucción la genera el dorso de la lengua contra el paladar, son sonidos palatales (prepalatal o pospalatal según sea más adelante o más atrás), y si la obstrucción la genera el dorso de la lengua contra el velo del paladar son sonidos velares. Observen el cambio de sonido si pronuncian pa, ta, cha y ca. Fonéticamente, según AFI, [pa], [ta], [ça] y [ka]: bilabial, dental, (pre)palatal y velar.
Hay otro rasgo que diferencia el sonido [m] del sonido [f]. Vuelvan a pronunciar ambas secuencias [eme] y [efe] mientras apoyan suavemente los dedos en el cuello. ¿Recuerdan? Si vibra el cuello significa que vibran las cuerdas vocales, y que nos encontramos frente a un sonido sonoro. En cambio, si las cuerdas no vibran, el sonido es sordo. Vuelvan a mantener [ffff] y [mmmm]. ¿Cuál es sorda y cuál sonora?
Las consonantes, además, pueden caracterizarse por dónde sale el aire. Si el aire es expulsado por el costado de la boca, las consonantes son laterales, como [l] y [r]; si se producen minúsculas interrupciones durante su realización, son vibrantes (o róticas), como los sonidos [r] o [R] (vibrante simple o múltiple): calo, caro, carro.
Cuando el canal bucal está cerrado, el aire se expulsa por la cavidad nasal, y los sonidos consonánticos poseen el rasgo de nasalidad. En el español, hay dos consonantes nasales. Hagan la prueba… vuelvan a mantener el sonido [mmm] y mientras lo pronuncian, tápense la nariz. ¿Qué pasa? [m] y [n] son consonantes nasales en español. También eñe…
Desde el punto de vista articulatorio, las consonantes sonantes se diferencian entre sí por la forma en que se expulsa el aire durante su pronunciación. En las laterales, el aire se expulsa por los lados de la cavidad bucal a ambos lados de la lengua; en las nasales, por la cavidad nasal, y, en las vibrantes, se agrega el movimiento vibratorio de la lengua.
Consonantes y vocales juntas
Cuando pronunciamos los distintos sonidos lingüísticos, los límites entre un sonido y otro no son categóricos, sino que hay un acomodamiento de los órganos que se preparan para el sonido siguiente mientras están pronunciando uno. Esto puede verse claramente en el último video, en el que una hablante de inglés pronuncia diferentes palabras que se distinguen sólo por el acento. Observen cómo se modifica la articulación en cada caso.
FONOLOGÍA
Hasta ahora, sabemos que los hablantes de cualquier lengua utilizamos sonidos para transmitir significados (Gramática y análisis gramatical). También sabemos de qué manera usamos nuestros órganos para producir sonidos (Fonética articulatoria) y cómo se pueden describir acústicamente los sonidos del habla (Fonética acústica).
Recordemos que toda la investigación gramatical se maneja entre dos márgenes: el sonido y el significado. ¿Cómo se vinculan, cómo se logra que una secuencia de sonidos determinada se entienda de cierta manera y no de otra?
Dijimos que la fonética estudia los sonidos y la semántica los significados, y llamamos forma lingüística a cualquier secuencia de sonidos de una lengua que tenga significado.
Sin embargo, no hemos dicho absolutamente nada acerca de qué es lo que hace que esos sonidos sean sonidos lingüísticos. ¿Qué hace que un sonido sea lingüístico o no? Escuchen. ¿Cuáles de estos sonidos son sonidos lingüísticos?
Podemos toser y hacer un sonido velar, y sin embargo, no consideramos que eso sea un sonido lingüístico. Podemos masticar, abriendo y cerrando los labios y moviendo la mandíbula, generando sonidos obstruyentes, y sin embargo no consideramos que esos sonidos sean sonidos lingüísticos. ¿Por qué no? Porque no son formas lingüísticas.
Recordemos que los métodos de análisis gramatical nos permitían identificar las formas lingüísticas por medio de varias operaciones. El método de análisis gramatical más simple es segmentar y sustituir. Si al cortar y reemplazar el resultado se integra, es decir, tiene significado, podemos decir que el segmento que reemplazamos es una forma lingüística. ´
Secuencia a analizar: [ema] (lo escribimos entre corchetes porque estamos analizando sonidos)
1. [e] [m] [a] (segmentamos en unidades de sonido)
2. [e] [s] [a] (sustituimos [m] por [s].
3. Integramos. ¿Tiene significado? Sí. “Esa” es una palabra posible y existente en español.
4. Conclusión: /s/ y /m/ son formas lingüísticas ya que pueden sustituirse en el mismo contexto y producir significado.
Observen que ya no escribí [m] ni [s] sino /m/ y /s/. Escribimos entre corchetes cuando transcribimos fonéticamente para analizar las propiedades fónicas, pero escribimos entre barras para señalar que se trata de formas lingüísticas. Las formas lingüísticas mínimas o segmentos (porque pueden segmentarse) que no tienen significado en sí mismas pero permiten distinguir significados son los fonemas.
Desde una perspectiva fonética, los fonemas son la representación abstracta de los sonidos de una lengua. Un fonema es una unidad de sonido abstracta. Una abstracción, no una entidad sonora real. Por lo tanto, los fonemas no pueden medirse. Solo se pueden medir físicamente las realizaciones concretas de los fonemas, es decir, los alófonos. Si se cambia un fonema (i.e. una unidad de sonido abstracta) por otro, se pueden obtener diferentes palabras de la lengua: sabemos que /l/, /n/ y /s/ son fonemas del español porque podemos cambiarlos en el mismo contexto sonoro y obtener palabras diferentes: pela, pena, pesa. Es decir que el término fonema se refiere a un sonido contrastivo en una lengua determinada. Los fonemas siempre pertenecen a una lengua específica. Cada lengua tiene un repertorio cerrado de fonemas.
Entonces, cuando estudiamos el sonido desde una perspectiva gramatical, en particular desde la fonología (que es la disciplina que estudia el sonido en relación con el significado y con la estructura gramatical), el fonema es la mínima forma lingüística que permite distinguir significados. Observen que el fonema NO TIENE significado, pero al reemplazar un fonema por otro podemos obtener formas lingüísticas con significados diferentes.
Desde una perspectiva fonológica un fonema es la forma lingüística mínima que permite distinguir significados
Dos palabras que solo se diferencian en un sonido y tienen significados diferentes forman un par mínimo. Encontrar pares mínimos permite identificar los fonemas de una lengua. La convención es escribir los fonemas entre barras oblicuas / /, para dejar en claro que nos estamos refiriendo a los sonidos contrastivos o fonemas y no a la ortografía (grafema o letra) ni a la pronunciación concreta (alófono).
La ortografía tradicional de las lenguas que utilizan un alfabeto como el nuestro se basa en general en el principio fonémico de utilizar una letra para cada sonido contrastivo, aunque por motivos de índole diacrónicos (i.e históricos) las ortografías convencionales suelen apartarse de este principio en mayor o en menor medida. Aunque el español tiene una ortografía que guarda una importante correspondencia entre grafema (i.e. letra) y fonema, esa correspondencia no es perfecta.
La palabra queso se compone de cuatro fonemas y se transcribe fonológicamente /k/ /e/ /s/ /o/. Observen que NO HAY una correspondencia uno a uno entre fonema y letra, ya que el fonema /k/ a veces se representa por la letra c, otras por k y otras por qu:
caso / queso quiso / kilo
LOS FONEMAS VOCÁLICOS DEL ESPAÑOL
El sistema vocálico del español está constituido por cinco unidades: /a/ /e/ /i/ /o/ y /u/. Uno de sus rasgos característicos es la simplicidad. Existen lenguas que tienen sistemas vocálicos mucho más complejos, como el inglés (12 vocales en el inglés británico). Otras lenguas, como el árabe, poseen un sistema vocálico integrado por solo tres segmentos.
/paso/ /peso/ /piso/ /poso/ /puso/
Como vimos, las vocales son los sonidos que se perciben y producen con mayor facilidad, ya que durante su producción el flujo de aire no encuentra ningún obstáculo en su salida. Todas las vocales son sonoras, pues se generan con vibración de las cuerdas vocales.
Acústicamente, los sonidos vocálicos están constituidos por una onda sonora periódica compleja, que experimenta resonancia cuando atraviesa las cavidades y, de este modo, se amplifican algunos de sus armónicos. Es decir que las vocales tienen estructura formántica. Los parámetros acústicos más importantes para identificar las vocales son los valores de la frecuencia de los dos primeros conjuntos de armónicos amplificados o formantes F1 y F2.
Desde el punto de vista articulatorio, en la clasificación de las vocales del español se consideran la abertura oral, la posición de la lengua y el redondeamiento.
La abertura la determina la posición más o menos elevada de la mandíbula inferior y la distancia entre la lengua y la parte superior de la cavidad oral. De acuerdo con este parámetro, las vocales pueden ser abiertas y cerradas.
La posición de la lengua distingue entre vocales anteriores y posteriores. Las vocales anteriores son [i], [e]. Las posteriores, [o], [u]. La vocal [a] es una vocal baja central.
Estas diferencias permiten graficar las diferencias articulatorias de las vocales del español en un triángulo.

Existe una correspondencia entre el espacio articulatorio de cada vocal como se describe en la tabla del AFI (Alfabeto Fonético Internacional) y el espacio acústico de cada vocal (frecuencia de formantes).

Los primeros dos formantes, F1 y F2, corresponden a la altura de la vocal y a su anterioridad / posterioridad, respectivamente, y se trazan en una carta de formantes para graficar el espacio acústico que ocupa cada vocal. Cuanto más alta es la vocal, más bajo es el F1 (i.e. la vocal alta del español /i/ tiene un F1 promedio de 369 Hz) y cuanto más posterior es la vocal, más bajo es el F2 (i.e. la vocal española /u/ es posterior y su F2 promedio es de 937 Hz) (Datos de Ladefoged, (1993), de acuerdo con los valores reportados en el trabajo de Martínez Celdrán (1995).

La carta de formantes es una representación de la relación entre el F1 y el F2 en un eje de coordenadas, con los valores del F1 en el eje vertical y los valores del F2 en el eje horizontal. La escala del F1 va desde los 750hz (en la parte inferior del gráfico) hasta 150hz (en la parte superior del gráfico). Por otro lado, la escala del F2 va desde 900hz (a la derecha) hasta más allá de los 2400 hz (a la izquierda) (recuerden que el F1 y el F2 son múltiplos del F0, por lo que siempre el F2 es mucho mayor). Estos límites de frecuencias no son absolutos, por lo que pueden presentar ciertas variaciones.

Vocales altas o cerradas: [ i ]-[ u ]
Estas vocales se diferencian entre sí por el adelantamiento de la lengua. Durante la pronunciación de [i] la posición de la lengua está muy adelantada, mientras que durante la pronunciación de [u], la lengua se encuentra en la parte posterior de la cavidad bucal. El primer formante (F1) de las vocales está relacionado con su grado de abertura. Cuanto más cerrada es la vocal, más baja es la frecuencia del F1. Así, los primeros formantes de las vocales [i] y [u] son los que presentan valores más graves, más bajos, en el sistema del español. El segundo formante (F2) de las vocales está relacionado con la posición de la lengua. Cuanto más adelantada, más elevada es la frecuencia del segundo formante y, cuanto más posterior es la vocal, más grave (más baja) es la frecuencia del segundo formante. Consecuentemente, las vocales [i] y se distinguen entre sí por los valores del segundo formante.
Vocales medias [ e ]-[ o ]

Durante la realización de [ e ] y [ o ] presentan, en español, un grado de abertura mayor que para [i]-[u]. Las dos vocales se diferencian entre sí por la posición de la lengua. Durante la pronunciación de [e], la posición de la lengua está mucho adelante pero no tanto como la [i]. Para pronunciar la [o], en cambio, la lengua está situada en la parte posterior de la cavidad bucal, pero no tanto como la [u]. Acústicamente, el primer formante de ambas vocales es más alto que el de [i] y [u], porque son vocales más abiertas. Se diferencian entre sí porque, durante la pronunciación de [e], la lengua está más adelantada que durante la pronunciación de [o], que es una vocal posterior; por tanto, los valores del segundo formante de [e] son altos, y los del segundo formante de[o], bajos.
Vocal [ a ]
La vocal [a] presenta un grado máximo de abertura en español. En la pronunciación de [a] la lengua se encuentra en una posición intermedia en el canal bucal. La vocal es, por tanto, abierta y central.
Acústicamente, el primer formante de la vocal presenta los valores más altos de frecuencia del sistema del español, ya que es la vocal más abierta. Los valores del segundo formante son intermedios entre los de [e] e [i] —más elevados, pues la lengua está en una posición más adelantada— y los de [o] y [u] —más bajos, porque la lengua está en una posición más retrasada.
FONEMAS CONSONÁNTICOS DEL ESPAÑOL
FONEMAS CONSONÁNTICOS OBSTRUYENTES
En el español rioplatense existen tres clases de consonantes obstruyentes:
- Oclusivas: /p/ /t/ /k/ /b/ /d/ /g/
- Fricativas: /f/ /s/ /j/
- Africadas /ch/ (En la realización de la consonante africada, se combina una fase de cierre con una abertura parcial del canal oral; el aire sale primero en forma de explosión y, posteriormente, en forma de fricción o ruido.)
Una aclaración: solo por razones de claridad expositiva utilizaremos una transcripción fonética simplificada en la que acercaremos la representación más a los grafemas del español que al AFI. Así, /ch/ representa el sonido de che, /j/ representa el sonido de jota, /y/ representa el sonido de yo en el español rioplatense ((pre)palatal sordo) y /rr/ representa el sonido de rosa y perro. Hacemos esto para facilitarles la lectura, pero sepan que no es lo que corresponde en el trabajo fonológico estricto y mucho menos en el trabajo fonético.
Además, según presenten o no vibración en las cuerdas vocales, las consonantes obstruyentes pueden ser sordas /p/, /t/, /k/, /y/ /ch/ /j/ o sonoras //b/, /d/ /g/.
Desde el punto de vista acústico, la representación de las consonantes obstruyentes en el espectrograma varía en función de sus características articulatorias. La ausencia de sonoridad en la fase de obstrucción de las oclusivas y africadas se manifiesta con un espacio en blanco en el espectrograma.
En cambio, la fase de fricción de las fricativas aparece representada por energía sonora aperiódica en zonas de elevada frecuencia del espectrograma.
La onda sonora de las obstruyentes sordas es la de un sonido no periódico y la de las sonoras presenta, además, la energía periódica que corresponde a la vibración de las cuerdas vocales.
Los fonemas consonánticos oclusivos.
Las consonantes oclusivas se caracterizan por que, durante su realización, se produce un obstáculo total a la salida del aire. La onda sonora propia de esta clase de consonantes es una impulsión.
El español posee seis segmentos consonánticos oclusivos: /p/,/t/,/k/,/b/,/d/ y /g/. Su realización fonética se distingue por la ausencia o presencia de vibración en las cuerdas vocales, que da lugar a las oclusivas sordas /p/,/t/ /k/, y a las sonoras /b/ /d/ /g/ respectivamente. Además, por el lugar o zona de articulación, las oclusivas se clasifican en bilabiales /p/, /b/ dentales (/t/,/d/) y velares /k/ y /g/.
Los segmentos oclusivos sonoros (/b/,/d/ y /g/ ) presentan distintas variantes de realización o alófonos. En la palabra dado, la primera consonante se realiza con mayor fuerza que la segunda. La primera corresponde a una realización oclusiva, y la segunda, a una realización aproximante casi fricativa.
Las realizaciones aproximantes presentan características que las acercan a las vocales y las diferencian de las consonantes. En su articulación, el canal por el que sale el aire es más ancho que en la fricativa, y no se produce la fricción originada por la turbulencia del aire al pasar entre los órganos articulatorios. Desde el punto de vista acústico, al no existir obstrucción, los formantes de los espectrogramas son semejantes a los de las vocales.
Desde el punto de vista articulatorio, la realización de las consonantes oclusivas comprende dos fases: una fase de cierre y otra de abertura. En la primera, los órganos articulatorios entran en contacto y forman un obstáculo total a la salida del aire; en la segunda, los órganos se separan bruscamente.
Desde el punto de vista acústico, las consonantes oclusivas sordas presentan la fase articulatoria de cierre caracterizada por la ausencia de energía sonora, lo que se corresponde con un espacio en blanco en el espectrograma. La fase de abertura se manifiesta con una zona muy breve de energía denominada barra de explosión.
Las consonantes oclusivas sonoras presentan las mismas características acústicas que las consonantes sordas (fase de cierre, fase de explosión y transiciones). La vibración de las cuerdas vocales se refleja en la barra de sonoridad, un formante situado en las zonas de frecuencia baja en el espectrograma.
Las consonantes fricativas
Las consonantes fricativas se caracterizan por que, durante su realización, se produce un obstáculo parcial en la cavidad oral y el aire, al ejercer presión para salir, origina una fricción.
La onda sonora correspondiente a esta clase de sonidos se denomina ruido.
El español rioplatense incluye cuatro segmentos fricativos: /f/, /s/, /j/ y /y/. La consonante /s/ presenta numerosas realizaciones diferentes o alófonos, el más frecuente de los cuales es la articulación predorsal acanalada.
Desde el punto de vista articulatorio, las consonantes fricativas se distinguen por el lugar o zona de articulación: labiodental en /f/, dento-alveolar o predorsal en /s/, palatal en /y/ y velar en /j/.
Por la acción de las cuerdas vocales, son todas sordas.
Desde el punto de vista acústico, las consonantes fricativas son sonidos aperiódicos, resultado de la fricción o turbulencia que el aire origina al atravesar el estrecho canal constituido por los órganos articulatorios.
Los fonemas consonánticos nasales
Las consonantes nasales se caracterizan por que, durante su realización, el canal bucal está cerrado y el aire sale por la cavidad nasal.
Estas consonantes son sonoras, puesto que durante su emisión vibran las cuerdas vocales. La onda sonora propia de las nasales es periódica.
El español presenta tres segmentos nasales, /m/, /n/ y /ñ/, que se diferencian entre sí por el lugar o zona de articulación: bilabial en /m/, alveolar en /n/y palatal en /ñ/.
Desde el punto de vista articulatorio, los sonidos nasales se producen por la acción de dos resonadores: el oral y el nasal. El canal bucal está cerrado, como en la articulación de las consonantes oclusivas, aunque la úvula no se encuentra en contacto con la pared faríngea y el aire sale a través de las fosas nasales sin fricción ni turbulencia.
Desde el punto de vista acústico, las consonantes nasales tienen características similares a las consonantes oclusivas. En el espectrograma, los sonidos nasales poseen estructura formántica y presentan un formante específico denominado formante nasal, que se debe a la resonancia producida cuando el aire es expulsado por las fosas nasales.
Las vibrantes
Las consonantes vibrantes, también llamadas róticas, se caracterizan por que, durante su realización, se producen fases de cierre y de abertura de los órganos articulatorios, que permiten la salida del aire por la cavidad oral.
Las consonantes vibrantes son sonoras y su onda sonora es periódica.
El español posee dos segmentos vibrantes: /r/ y /rr/ . Estas consonantes se distinguen por el número de fases de abertura y cierre de los órganos fonatorios.
Desde el punto de vista articulatorio, la consonante vibrante simple, se identifica por articularse con una única fase de cierre; la consonante vibrante múltiple, presenta dos o más momentos de oclusión, separados por fases de abertura. La zona de articulación de ambas consonantes es alveolar.
Laterales
Las consonantes laterales se caracterizan por que, durante su realización, la lengua se sitúa en el centro de la cavidad bucal y el aire se expulsa por los lados.
Estas consonantes son sonoras, pues se generan mediante la vibración de las cuerdas vocales, y, por tanto, su onda sonora es periódica.
El español rioplatense posee un solo segmento lateral, /l/ de articulación alveolar.
Desde el punto de vista acústico, la vibración de las cuerdas vocales se refleja en la barra de sonoridad, un formante situado en las zonas de frecuencia baja en el espectrograma. Al no existir obstrucción total a la salida del aire, las cavidades supraglóticas actúan como caja de resonancia y, por tanto, las consonantes laterales presentan una estructura formántica semejante a la de las vocales, aunque de intensidad más baja.
Las africadas
Las consonantes africadas se caracterizan por que, durante su realización, se produce un obstáculo total a la salida del aire (explosión) y, seguidamente, un obstáculo parcial (fricción).
La onda sonora propia de este tipo de consonantes se compone de una explosión y un ruido de fricción.
El español rioplatense posee un único segmento africado, /ch/.
Desde el punto de vista articulatorio, la consonante se realiza con el predorso de la lengua contra la región palatal dos fases distintas: una fase de oclusión y otra de fricción. En la primera, la lengua entra en contacto con el paladar y se interrumpe la salida del aire; en la segunda, se produce una pequeña separación de estos órganos y el aire sale en forma de ruido de fricción. Desde el punto de vista acústico, la consonante posee una fuente aperiódica en la cavidad oral.
La consonante se refleja en el espectrograma con un espacio en blanco, seguido de una zona muy breve de energía llamada barra de explosión. A continuación, la energía sonora sale de la cavidad bucal en forma de ruido de fricción, y se manifiesta en el espectrograma mediante una onda sonora aperiódica distribuida en diferentes zonas en la escala de frecuencias.
Continúa en FONOLOGÍA SUPRASEGMENTAL
Este material fue redactado por Andrea Menegotto como parte de sus clases de Gramática I en la Universidad Nacional de Mar del Plata, para los cursos 2016 y 2017, a partir de las siguientes fuentes básicas:
Gurlekian, J. A., Colantoni, L. y Torres, H. (2001). “El alfabeto fonético SAMPA y el diseño de corpora fonéticamente balanceados”. Fonoaudiológica. Editorial: ASALFA. Tomo: 47, Numero: 3, pp 58-69.
Hualde, J. I., Olarrea, A., Escobar, A. M., & Travis, C. E. (2009). Introducción a la lingüística hispánica. Cambridge University Press.
Real Academia Española. Nueva gramática de la lengua española: Fonética y fonología. Espasa Libros, 2011. Las voces del español. DVD.
http://sail.usc.edu/span/resources.html
Por favor, para reutilizar el material o comentarlo, comunicarse con acmenegotto@gmail.com
LAS SÍLABAS DEL ESPAÑOL
SUPRASEGMENTOS FONOLÓGICOS
Entonación y significado
Toda secuencia de palabras con significado tiene, necesariamente, alguna entonación particular o rasgos prosódicos. Los rasgos prosódicos nos permiten, entre otras cosas, diferenciar la modalidad de las oraciones según su entonación en declarativas (asertivas afirmativas o negativas y dubitativas), interrogativas, exhortativas y apelativas.
Viene. (Declarativa asertiva afirmativa)
No viene (Declarativa asertiva negativa)
Tal vez venga (Dubitativa)
¿Viene? (Interrogativa)
¡Viene! (Exclamativa)
¡Dale, vení! (Apelativa)
FOCO
En general, los ítems que ya han sido nombrados en el discurso o los que se presupone que se comparten con el interlocutor (llamados, semánticamente, información dada) son prosódicamente menos relevantes que los que llevan la información nueva. Tanto es así que, en español, la información dada en función sujeto puede omitirse totalmente y estar prosódicamente ausente.
El foco es un fragmento del enunciado acentuado o destacado prosódicamente. Habitualmente se trata del fragmento que lleva la información no presupuesta o no compartida por los interlocutores. La mayor prominencia se concreta como una prominencia tonal, es decir, el foco es la subida tonal de un fragmento del enunciado respecto de los tonos precedentes. Todos los enunciados tienen algún foco, es decir, algún fragmento que se destaca tonalmente del resto.
El método gramatical para identificar el foco de una oración declarativa es contextualizar el enunciado partiendo del supuesto de que una oración declarativa es la respuesta a una pregunta supuesta o implicada. Así, podemos delimitar el foco a partir de la prueba de la pregunta-respuesta. La pregunta constituye el contexto previo que motiva la respuesta, donde efectivamente aparece el foco. La prueba de la interrogación es uno de los métodos experimentales habituales para provocar que uno o más ítems léxicos o toda la oración se focalicen a partir de preguntas pronominales previas. Así, por ejemplo, a partir de la pregunta pronominal [2] se obtiene la declarativa [3], que es en su conjunto el foco, en tanto no es presupuesta por los interlocutores.
[2] – ¿Qué pasó?
[3] – Un cura denunció a unos narcos en Itatí.
En cambio, si el contexto es la pregunta [4], en [5] el sujeto constituye la presuposición y el predicado es el foco [F].

[4] ¿Qué hizo?
[5] El cura [F denunció a los narcos de Itatí].
De los ejemplos anteriores se deriva, entonces, que el foco puede variar de extensión. Así, toda una oración puede estar focalizada como es el caso del ejemplo [3], en cuyo caso se habla de foco neutro o normal; también se puede focalizar sólo una parte de la oración como es el caso del ejemplo [5] donde está focalizado sólo el predicado, en cuyo caso se habla de foco amplio; el foco puede identificarse también con un solo constituyente o incluso una sola palabra, en cuyo caso se habla de foco restringido o estrecho como en el ejemplo de [6]
[6] a. Contexto: ¿Qué compró María?
b. María compró [F un traje]
La prueba de la interrogación nos permite ver cómo, partiendo del contexto interrogativo [7], el foco en [8] se situaría al final.
[7] ¿Dónde compraste el traje?
[8] Lo compré [F en el shopping].

En cambio, ante la pregunta [9], en la respuesta [10] el foco puede situarse al inicio o al final.
9] ¿Quién compró el traje?
[10] [F María] lo compró // Lo compró [F María]
![El cura denunció [F a los narcos de Itatí]](https://lasclasesdemenegotto.com.ar/wp-content/uploads/2021/03/f9f70-focosimple-1491229796-34-1.jpg)
La prominencia prosódica permite desambiguar el ámbito del foco. En una oración declarativa escrita y aislada, como [11], no podemos saber cuál es el foco sin saber el contexto de producción.
[11] El cura denunció a los narcos de Itatí.
Gramaticalmente, entonces, tenemos que identificar si esa oración declarativa aislada es la respuesta a 12a, 12b o 12c.
[12] a. ¿Qué ocurrió?
b. ¿Qué hizo el cura?
c. ¿A quién denunció el cura?
Según la pregunta que supongamos, el foco puede ser toda la cláusula como en [13a], el predicado verbal como en [13 b] o el objeto directo como en [13 c]
[13] a. [F El cura denunció a los narcos de Itatí]
b. El cura [F denunció a los narcos de Itatí]
c. El cura denunció [F a los narcos de Itatí]
Todos estos son ejemplos de focos no marcados, de estructuras esperadas en la interacción discursiva. Existen, además, otros patrones prosódicos que marcan una emisión contra-expectativa, es decir, inesperada en relación con la interacción discursiva. El caso más característico es el foco contrastivo, en el que se destaca algún segmento de la emisión para contrastarlo que algo que ya se haya mencionado (A), pero para señalar que no es A, sino B.
-Fui al cine con las chicas.
– Sí, claro. Fuiste al cine CON TU NOVIO.